The Comprehensive Guide to Writing Firetasks with Python¶
This guide covers in more detail how one can write their own Firetasks (and return dynamic actions), and assemble those Firetasks into FireWorks and Workflows. This guide will also cover the FWAction object, passing data, and dynamic workflow actions.
A “Hello World Example”¶
If you’d like to see a “Hello World” Example of a custom Firetask, you can go here.
If you are able to run that example and want more details of how to modify and extend it, read on…
Writing a Basic Firetask¶
Step 1: Choose existing Firetask(s) or write your own?¶
The first thing you should decide is whether to use an existing Firetask or write your own. FireWorks comes pre-packaged with many “default” Firetasks - in particular, the PyTask allows you to call any Python function. There are also existing Firetasks for running scripts, remotely transferring files, etc. The quickest route to getting something running is to use an existing Firetask, i.e. use the PyTask if you want to run a quick script.
Links to documentation on default Firetasks can be found in the main page under the heading “built-in Firetasks”.
A few reasons to not use the default Firetasks are:
You want to give your Firetasks custom names
You prefer a class-based method to defining tasks rather than the function-based method of PyTask
You want control over how the Firetask is constructed, e.g., define required parameters.
Step 2: Start with a Firetask template and modify it¶
The easiest way to understand a Firetask is to examine an example; for example, here’s one implementation of a task to archive files:
class ArchiveDirTask(FiretaskBase):
"""
Wrapper around shutil.make_archive to make tar archives.
Args:
base_name (str): Name of the file to create.
format (str): Optional. one of "zip", "tar", "bztar" or "gztar".
"""
_fw_name = 'ArchiveDirTask'
required_params = ["base_name"]
optional_params = ["format"]
def run_task(self, fw_spec):
shutil.make_archive(self["base_name"], format=self.get("format", "gztar"), root_dir=".")
You can copy this code to a new place and make the following modifications in order to write your Firetask:
- In the first line, the name of the class (ArchiveDirTask) can be anything - it does not affect the operation of the code if you follow the structure above.
Change the class name to anything you desire.
- The class extends the FiretaskBase abstract class. This abstract class does some work under the covers and also requires that you define a
run_task(self, fw_spec)method. Keep this intact.
- The class extends the FiretaskBase abstract class. This abstract class does some work under the covers and also requires that you define a
- The
_fw_nameis how this Firetask is identified. It must be a unique name that is always retained. See the Appendix section for working around this and an alternate formulations for identifying the Firetask. Change the ``fw_name`` value to a desired identifier for your Firetask, e.g. MyFavoriteTask.
- The
- The
required_paramsandoptional_paramsrelate to how the Firetask is constructed. As a developer, you can choose whether to add these variables or not - if you do set them, they help with safety and also documentation, thus they are recommended. In the example above, an ArchiveTask could be instantiated using something likemy_task = ArchiveTask(base_name="my_filename", format="bztar"). Becausebase_nameis inrequired_params, it must be specified by the user or the FireTask will throw an error. Becauseoptional_paramsis also set in this example, the Firetask will perform an additional safety check: it will throw an error if the user attempts to initializeArchiveTaskwith any keyword arguments other than those listed in eitherrequired_paramsoroptional_params. Add your required and optional parameters as desired.
- The
- The meat of the Firetask is the
run_task(self, fw_spec)method. It has two sources of information: the keys infw_specand a dictionary ofself(which includes parameters likebase_nameused to construct the object). In this case, it’s tarring and gzipping some files according to the parameters the dictionary of itself, and ignoring anything in thefw_spec. Keep the run_task method header intact, but change the definition to your custom operation. Remember you can access dict keys of “fw_spec” as well as dict keys of “self”
- The meat of the Firetask is the
Step 3: Register your Firetask¶
When FireWorks bootstraps your Firetask from a database definition, it needs to know where to look for Firetasks.
First, you need to make sure your Firetask is defined in a file location that can be found by Python, i.e. is within Python’s search path and that you can import your Firetask in a Python shell. If Python cannot import your code (e.g., from the shell), neither can FireWorks. This step usually means either installing the code into your site-packages directory (where many Python tools install code) or modifying your PYTHONPATH environment variable to include the location of the Firetask. You can see the locations where Python looks for code by typing import sys followed by print(sys.path). If you are unfamiliar with this topic, some more details about this process can be found here, or try Googling “how does Python find modules?”
Second, you must register your Firetask so that it can be found by the FireWorks software. There are a couple of options for registering your Firetask (you only need to do one of the below):
Use the @explicit_serialize decorator to define your FW name (see the Appendix). No further registration is needed if you use this option.
(or) if you have access to the FireWorks source directory, put your Firetask definition anywhere in
fireworks.user_objectsor it subdirectories - it will be automatically be found there.(or) put the Firetask wherever you’d like. However, you need to modify the
USER_PACKAGESvariable of the FW config to include the package for where to find the Firetask, e.g. “mypackage.my_subpackage”. Note that FireWorks will search within subpackages automatically, so you can just put a root package (but loading will be slightly slower).
You are now ready to use your Firetask!
Dynamic and message-passing Workflows¶
In the previous example, the run_task method did not return anything, nor does it pass data to downstream Firetasks or FireWorks. Remember that the setting the _pass_job_info key in the Firework spec to True will automatically pass information about the current job to the child job - see reference for more details.
However, one can also return a FWAction object that performs many powerful actions including dynamic workflows.
Here’s an example of a Firetask implementation that includes dynamic actions via the FWAction object:
class FibonacciAdderTask(FiretaskBase):
_fw_name = "Fibonacci Adder Task"
def run_task(self, fw_spec):
smaller = fw_spec['smaller']
larger = fw_spec['larger']
stop_point = fw_spec['stop_point']
m_sum = smaller + larger
if m_sum < stop_point:
print(f"The next Fibonacci number is: {m_sum}")
# create a new Fibonacci Adder to add to the workflow
new_fw = Firework(FibonacciAdderTask(), {"smaller": larger, "larger": m_sum, "stop_point": stop_point})
return FWAction(stored_data={"next_fibnum": m_sum}, additions=new_fw)
else:
print(f"We have now exceeded our limit; (the next Fibonacci number would have been: {m_sum})")
return FWAction()
We discussed running this example in the Dynamic Workflow tutorial - if you have not gone through that tutorial, we strongly suggest you do so now (it also includes an example of message passing).
Note that this example is slightly different than the previous one:
We did not define any required or optional parameters. The parameters are taken from the
fw_specrather thanself.We are explicitly returning FWAction objects. In one case, the object looks to be storing data and adding FireWorks.
Other than those differences, the code is the same format as earlier. The dynamicism comes only from the FWAction object; next, we will describe this object in more detail.
File-passing Workflows¶
In many common types of workflows, you want to pass files from one Firework to the next. For example, the output files generated by one Firework may be used by the next Firework as an input.
FireWorks support two keys - _files_in and files_out - as a means to specifying the expected input and output
files for a Firework. See reference for more details.
An example of such a workflow is given below:
fw1 = Firework(
[ScriptTask.from_str('echo "This is the first FireWork" > test1')],
spec={"_files_out": {"fwtest1": "test1"}}, fw_id=1)
fw2 = Firework([ScriptTask.from_str('gzip hello')], fw_id=2,
parents=[fw1],
spec={"_files_in": {"fwtest1": "hello"},
"_files_out": {"fw2": "hello.gz"}})
fw3 = Firework([ScriptTask.from_str('cat fwtest.2')], fw_id=3,
parents=[fw2],
spec={"_files_in": {"fw2": "fwtest.2"}})
wf = Workflow([fw1, fw2, fw3],
{fw1: [fw2], fw2: [fw3]})
Both _files_in and _files_out are dicts of {mapped_name: actual_file_name}. If the child Firework has _files_in
that intersects with files_out of the parent, these files are automatically copied over and renamed, with gzip,
bzip2 compression being handled transparently. In the above example, fw1 generates a file called test1, which
is available in _files_out under the name fwtest1. The files_in of fw2 contains fwtest1, which means that
the file test1 is being copied to the launch directory of fw2 and renamed as hello. The same concept applies
to fw2 and fw3, though in this case, the gzipped file of fw2 is moved to the launch directory of fw3, ungzipped and
made available as fwtest.2. Note that the mapped names must conform to MongoDB rules, i.e., no “.” and “$” cannot be
the first character. There are no restrictions on the actual file name.
This framework completely decouples the input and output file names between linked Fireworks for flexibility, and also makes it easier for most Fireworks to make use of compression where necessary to reduce storage requirements without requiring child fireworks to implement complex logic for handling compressed files. The FW spec also becomes a complete definition of expected input and output files, a very common use case in many sophisticated workflows.
The FWAction object¶
A Firetask (or a function called by PyTask) can return a FWAction object that can perform many powerful actions. Note that the FWAction is stored in the FW database after execution, so you can always go back and see what actions were returned by different Firetasks. A diagram of the different FWActions is below:
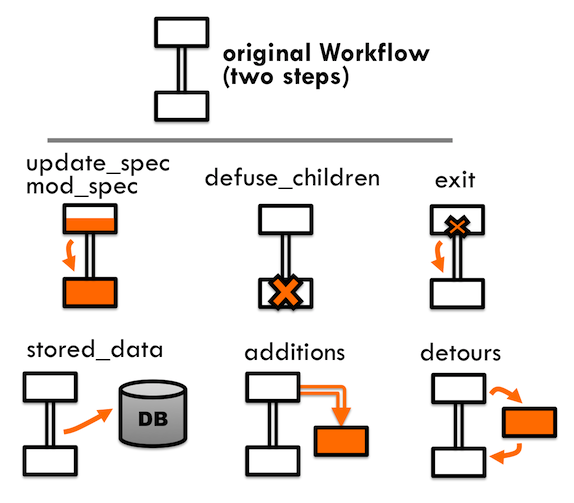
The parameters of FWAction are as follows:
stored_data: (dict) Data to store from the run. The data is put in the launches collection of the database along with the rest of the FWAction. Does not affect the operation of FireWorks.
exit: (bool) If set to
True, all remaining Firetasks within the same Firework are skipped (like abreakstatement for a Firework). Default isFalse.update_spec: (dict) A data dict that will update the spec for any remaining Firetasks and the following Firework. Thus, this parameter can be used to pass data between Firetasks or between FireWorks. Note that if the original fw_spec and the update_spec contain the same key, the original will be overwritten. Default is empty dict.
mod_spec: ([dict]) This has the same purpose as update_spec - to pass data between Firetasks/FireWorks. However, the update_spec option is limited in that it can’t increment variables or append to lists. This parameter allows one to update the child FW’s spec using the DictMod language, a Mongo-like syntax that allows more fine-grained changes to the fw_spec. Default is empty list.
additions: ([Workflow]) A list of WFs/FWs to add as children to this Firework, default is empty list.
detours: ([Workflow]) A list of WFs/FWs to add as children (they will inherit the current FW’s children), default is empty list
append_wfs ([dict]): Generalization of additions and detours with additional parents. The dictionary has this structure:
{'workflow': [Workflow], 'parents': [int], 'detour': bool}. An optional detour (whendetourisTrue) is applied to the current Firework (the one returning the FWAction). For the providedparentslist, only additions (no detours) are applied. Whenparentsis empty, this action is equivalent to eitherdetoursoradditionsactions, depending on thedetourvalue. Default is empty list.defuse_children: (bool) Defuse all the original children of this Firework, default is
False.defuse_workflow: (bool) Defuse all incomplete FWs in this Workflow, default is
False.propagate: (bool) Propagate spec modifications to all descendant Fireworks, default is
False.
The FWAction thereby allows you to command the workflow programmatically, allowing for the design of intelligent workflows that react dynamically to results.
Note
Currently, when a Firetask returns an FWAction with non-empty additions, detours, append_wfs, or defuse_children=True or defuse_workflow=True then exit=True is implied, i.e. all remaining Firetasks in the Firework are skipped.
Example: implement the if function¶
Here we can show that it is possible to implement the if function, c = if(x, a, b) as a Firetask by using a combination of FWAction parameters. The goal is to write a Firetask such that either the Firework providing a or the one providing b is linked as a parent and evaluated depending on the value of x. Thus, one of the if arguments is not evaluated. In the “usual” implementation, first both a and b are evaluated and only then one of them is used. The full example can be found here. Here, we will discuss only snippets.
After adding two Fireworks computing a and b we write a custom Firetask that creates a detour (if fw_if has children) or addition and linking one of these two Fireworks:
@explicit_serialize
class IfNonstrictTask(FiretaskBase):
required_params = ['condition', 'input_1', 'fw_id_1', 'input_2', 'fw_id_2',
'output'],
def run_task(self, fw_spec):
inp = self['input_1'] if fw_spec[self['condition']] else self['input_2']
fw_id = self['fw_id_1'] if fw_spec[self['condition']] else self['fw_id_2']
fwk = Firework(tasks=SummationTask(inputs=[inp], output=self['output']))
dct = {'detour': True, 'workflow': Workflow(fireworks=[fwk]), 'parents': [fw_id]}
return FWAction(append_wfs=dct)
@explicit_serialize
class SummationTask(FiretaskBase):
required_params = ['inputs', 'output']
def run_task(self, fw_spec):
inp = [fw_spec[i] for i in self['inputs']]
return FWAction(update_spec={self['output']: sum(inp)})
tsk_kwargs = {'detour_name': det_name, 'condition': 'x', 'input_1': 'a', 'input_2': 'b',
'fw_id_1': fw_1.fw_id, 'fw_id_2': fw_2.fw_id, 'output': 'c'}
fw_if = Firework(tasks=IfNonstrictTask(**tsk_kwargs), spec={'x': True})
The pairs of keys 'input_1', 'fw_id_1' and 'input_2', 'fw_id_2' refer to the values and the parent Firework IDs for a and b respectively. The key 'condition' is provided statically in the spec in this example ({'x': True}) but it can be pushed via update_spec by another Firework. After adding fw_if to LaunchPad and executing it, the IfNonstrictTask evaluates the condition and creates and, using append_wfs, appends dynamically a Firework which has the relevant Firework with fw_id as parent and passes the name of the selected inp (a or b). When the appended Firework is launched, the SummationTask passes the result using the key specified in output (here c) to the children Fireworks using update_spec. The SummationTask used in the detour/addition can be replaced by a more generic or more specialized Firetask.
Appendix 1: accessing the LaunchPad within the Firetask¶
It is generally no good practice to use the LaunchPad within the Firetask because this makes the task specification less explicit. For example, this could make duplicate checking more problematic. However, if you really need to access the LaunchPad within a Firetask, you can set the _add_launchpad_and_fw_id key of the Firework spec to be True. Then, your tasks will be able to access two new variables, launchpad (a LaunchPad object) and fw_id (an int), as members of your Firetask. One example is shown in the unit test test_add_lp_and_fw_id().
Appendix 2: alternate ways to identify the Firetask and changing the identification¶
Other than explicitly defining a _fw_name parameter, there are two alternate ways to identify the Firetask:
You can omit the
_fw_nameparameter altogether, and the code will then use the Class name as the identifier. However, note that this is dangerous as changing your Class name later on can break your code. In addition, if you have two Firetasks with the same name the code will throw an error.(or) You can omit the
_fw_nameand add an@explicit_serializedecorator to your Class. This will identify your class by the module name AND class name. This prevents namespace collisions, AND it allows you to skip registering your Firetask! However, the serialization is even more sensitive to refactoring: moving your Class to a different module will break the code, as will renaming it. Here’s an example of how to use the decorator:from fireworks.utilities.fw_utilities import explicit_serialize @explicit_serialize class PrintFW(FiretaskBase): def run_task(self, fw_spec): print str(fw_spec['print'])
In both cases of removing _fw_name, there is still a workaround if you refactor your code. The FW config has a parameter called FW_NAME_UPDATES that allows one to map old names to new ones via a dictionary of {<old name>:<new name>}. This method also works if you need to change your _fw_name for any reason.