Handling Duplicates Automatically¶
If you are running just a few jobs, or if your set of jobs is well-constrained, you may never have to worry about the possibility of duplicated runs. However, in some applications, duplicate jobs need to be explicitly prevented. This may be the case if:
Each job is a costly calculation that would be expensive to run again
The input data changes and grows over time. In this case, it might be difficult take a lot of user bookkeeping to track what input data was already processed and what workflow steps were already submitted.
Multiple users are submitting workflows, and two or more users might submit the same thing.
One way to prevent duplicate jobs is to pre-filter workflows yourself before submitting them to FireWorks. However, FireWorks includes a built-in, customizable duplicate checker. One advantage of this built-in duplicate checker is that it detects duplicates at the Firework (sub-workflow) level. Let’s see how this works.
Preventing Trivial Duplicates¶
A trivial duplicate might occur if two users submit the same workflow to the FireServer. Let’s see how this plays out when we have duplicate checking enabled for our workflows.
Move to the
duplicatestutorial directory in your installation directory:cd <INSTALL_DIR>/fw_tutorials/duplicates
Look inside the file
wf_12.yaml. This contains a workflow in which the first step adds the numbers 1+1, and the second step adds the number 2 to the result. Visually, the workflow looks like this: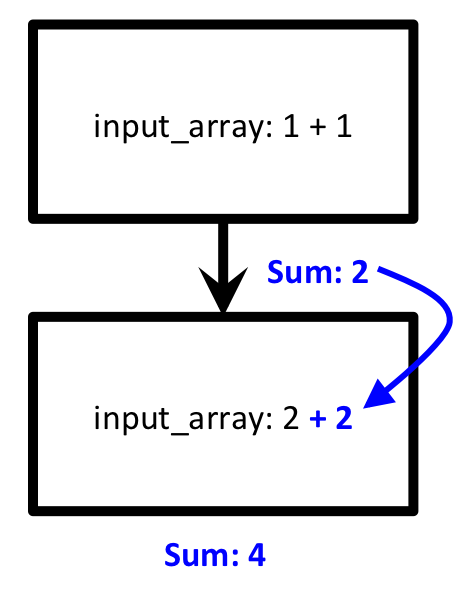
A schematic view of wf_12.yaml¶
After having completed the dynamic workflow tutorial, the contents of the file
wf_12.yamlshould be familiar to you; it is almost identical to theaddmod_wf.yamlfile that we examined in great detail for that tutorial. However, one section of this workflow is new, and looks like this:_dupefinder: _fw_name: DupeFinderExact
The
_dupefinderkey is a special key inside the Firework spec that tells us how to identify duplicates. TheDupeFinderExacttext refers to a built-in set of rules for finding duplicates; it considers two FireWorks to be the same if they contain the same spec.
Let’s add our workflow to the database and run it:
lpad reset lpad add wf_12.yaml rlaunch -s rapidfire
You should see two output directories, one corresponding to each section of the workflow. The standard out should have also printed the lines:
The sum of [1, 1] is: 2 The sum of [2, 2] is: 4
So far, there is nothing surprising; we defined a workflow and ran it. Let’s see what happens when we try to add back the same exact workflow:
lpad add wf_12.yaml
This completes successfully; the built-in duplicate checker will allow you to add in the same workflow twice. Let’s see what happens when we try to run this workflow:
rlaunch -s rapidfire
Nothing runs! Even though we added a new workflow, FireWorks did not actually run it because it was a duplicate of the previous workflow.
Instead of actually running the new FireWorks, FireWorks simply copied the launch data from the earlier, duplicated FireWorks. Let’s confirm that this is the case. Our first workflow had FireWorks with``fw_id`` 1 and 2, and our second workflow had FireWorks with
fw_id3 and 4:lpad get_fws -i 1 -d all lpad get_fws -i 2 -d all lpad get_fws -i 3 -d all lpad get_fws -i 4 -d all
All four FireWorks - both the ones we ran explicitly and the second set of duplicated runs - show Launch data as if they had been all been run explicitly.
In summary, when the _dupefinder key is specified, FireWorks allows users to submit duplicated runs, but actually runs only the workflows that are unique. A duplicated workflow has its run data copied from an earlier run (in other words, the duplicate run steals the launches of the original run). This process occurs when you run the Rocket Launcher - before running a Firework, the Rocket will check to see if it’s been run before. If so, it will just copy the Launch output from the previous Firework that had the same spec.
Sub-Workflow Duplicate Detection¶
One nice feature of FireWorks’ built-in duplicate detection is that it operates on a sub-workflow level. If only a portion of a workflow has been run before, FireWorks can avoid re-running that portion while still running unique sections, even within dynamic workflows.
Clear out your previous output in the
duplicatetutorials directory:rm -r launcher_*
Let’s add back our two-step workflow and run it:
lpad reset lpad add wf_12.yaml rlaunch -s rapidfire
As before, we should have run two FireWorks in agreement with our desired workflow. Now, let’s consider a situation where we insert a three-step workflow, but two of the steps are duplicated from before:
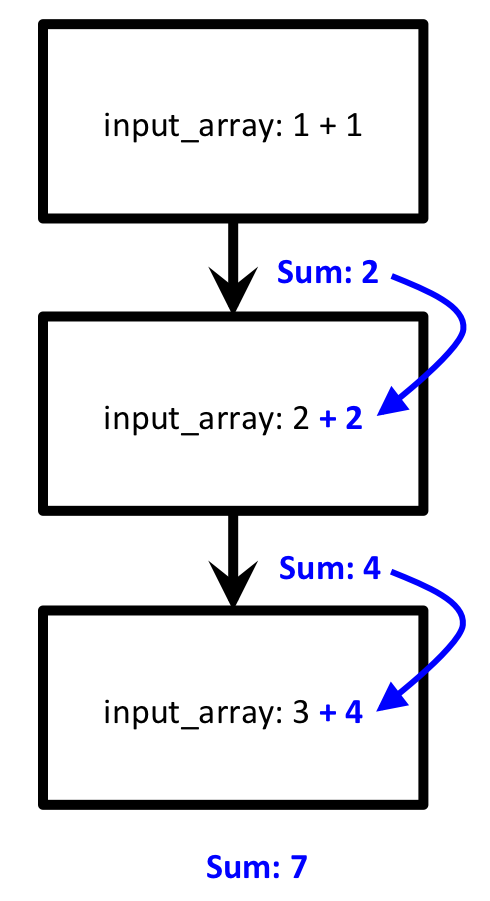
A schematic view of wf_123.yaml, which contains two steps common to wf_12.yaml¶
Ideally, we would want to only run the third step of the workflow from scratch, since it is unique. The first two steps we’ve already run before, and we can just copy the results from a past run. Let’s confirm that this is what happens when we run our new three-step workflow:
lpad add wf_123.yaml rlaunch -s rapidfire
You should see text in the standard out that reads:
The sum of [3, 4] is: 7
So indeed it looks like we skipped straight to the third step of our workflow (there was no text indicating that the first two steps ran explicitly). You can confirm that only one more
launcher_directory was added, meaning only the third addition took place!
In summary, with FireWorks’ duplicate checking you are free to submit many workflows in which some or all steps are duplicated from previous workflows. By enabling the _dupefinder field, only the new steps are actually run. The user can thus concentrate on submitting whatever workflows are of interest rather than doing the tedious bookkeeping of figuring out what steps of the workflow have been run before.
Performance and Customization¶
The built-in duplicate finder, Exact Dupe Finder, suffers from two limitations:
performance is not great when the number of FireWorks is large
matching is limited to exact matches of the Firework spec. You cannot, for example, define two FireWorks to be duplicated if a portion of the spec matches within some numerical tolerance.
In the future, we will include a tutorial on implementing custom Dupe Finders for your application that overcome these limitations. For now, we suggest that you refer to the internal docs or contact us for help. (see Contributing / Contact / Bug Reports). You can also try to improve performance by manually adding database indices to improve performance.
Adding a DupeFinder with Python¶
If you are creating a FireWork within Python and want to add in a DupeFinder object, create a key in your spec called _dupefinder and drop your DupeFinder object in there. For example:
from fireworks import Firework, ScriptTask
from fireworks.user_objects.dupefinders.dupefinder_exact import DupeFinderExact
fw = Firework([ScriptTask.from_str('echo "hello"')],
spec={"_dupefinder": DupeFinderExact()})