Database “Builders”¶
The Materials Project relies on MongoDB databases. The common parts of the
process of creating these databases from either files or other MongoDB databases
are encapsulated in the pymatgen.db.builders subpackage, and in the
mgbuild command-line script. This package and script
comprise a lightweight framework that is meant to
automate, simplify, and ultimately streamline the process of creating databases.
All the code and
methods are general-purpose, and thus could be useful to any project that needs
to perform extract-transform-load (ETL) operations with MongoDB.
The code presented here can be found in the directory pymatgen.db/builders/examples in the source code distribution.
Features¶
Parallel building¶
Builders can be run in parallel without explicit coding of parallelism by the author. This allows CPU-intensive transformations of the data to run much faster on multicore machines, which includes most modern hardware. An illustration of the difference between sequential and parallel builds is shown below.
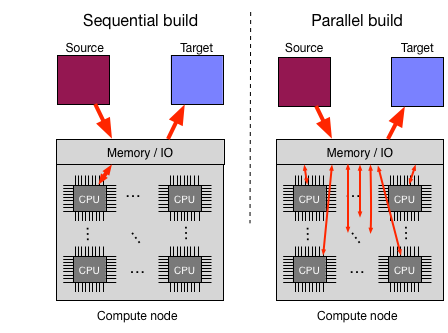
The builder framework automatically parallelizes the processing of
each item, by placing items in a shared queue and spawning processes to pull
items off the queue in parallel. Note that the get_items() method
is not automatically parallelized, so for better or worse
querying the DB happens sequentially (unless you write explicit parallel
code inside get_items()).
Incremental building¶
Incremental building allows successive builds of source MongoDB collection(s) to only operate on the records added since the last build. This can save huge amounts of time. An illustration of the difference between an incremental and full (non-incremental) build is shown below.
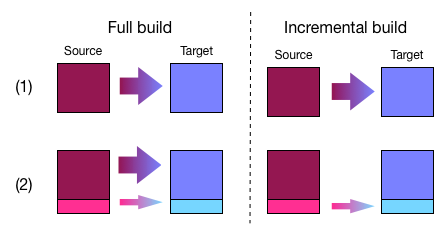
Writing a builder¶
To write a builder, you must create a Python class that inherits from pymatgen.db.builders.core.Builder (see the pymatgen.db.builders package) and implement a few methods on this class to perform the specific work for your builder. In this section we will give two example builders: a simple FileCounter builder that just counts the lines in a file, and a CopyBuilder that copies a MongoDB collection.
Simple “FileCounter” builder¶
The first builder simply reads from a file, and counts the lines in that file. In this section we’ll show the whole program, then walk through it one section at a time:
from pymatgen.db.builders.core import Builder
class FileCounter(Builder):
"""Count lines and characters in a file.
"""
def __init__(self, **kwargs):
self.num_lines = 0
Builder.__init__(self, **kwargs)
def get_parameters(self):
return {'input_file': {'type': 'str', 'desc': 'Input file path'}}
def get_items(self, input_file=None):
with open(input_file, "r") as f:
for line in f:
yield line
def process_item(self, item):
self.num_lines += 1
def finalize(self, errors):
print("{:d} lines, {:d} characters".format(
self.num_lines, self.num_chars))
return True
Initialization:
from pymatgen.db.builders.core import Builder
class FileCounter(Builder):
"""Count lines and characters in a file.
"""
def __init__(self, **kwargs):
self.num_lines = 0
Builder.__init__(self, **kwargs)
The class inherits from the pymatgen.db.core.Builder class. In this case, it includes
a constructor, but this is optional and often not needed. The constructor
simply initializes the number of lines counter and then calls its parent.
get_parameters:
def get_parameters(self):
return {'input_file': {'type': 'str', 'desc': 'Input file path'}}
This method returns a dictionary of metadata about the
parameters for get_items().
This metadata is used when running a builder with the mgbuild program.
More details on this are given in Running a builder.
For now, it is enough to note that the
parameters must match the keyword arguments to get_items(), both in
name and (expected) type.
get_items:
def get_items(self, input_file=None):
with open(input_file, "r") as f:
for line in f:
yield line
The two main methods that you must override are called get_items() and
process_item(). The first will return an iterator, in this case
the function simply returns one line of the file at a time.
Notice that you can make the function into a generator by using yield to
return items, but returning any other iterable would also work fine (e.g. the
function could have been a one-liner “return open(input_file).readlines()”).
process_item:
def process_item(self, item):
self.num_lines += 1
Here the instance variable num_lines is simply incremented for every
line passed to it by the get_items() iterator.
Warning
Updating instance variables will cause improper behavior if the user runs the builder in parallel. This occurs because the parallel mode automatically starts multiple copies of the same class, and their independent actions will clash. If you really need to update some shared state, use the Python multiprocessing module functions. See the multiprocessing docs for details.
finalize:
def finalize(self, errors):
print("{:d} lines, {:d} characters".format(
self.num_lines, self.num_chars))
return True
Optionally, you can put code that will be run once (for all builders) in
the finalize() method. Here we just print a result.
The return value of finalize is used to determine whether the build was
successful. So make sure you return True, if it succeeds, since the default
of None will read as False.
Note that this builder did not access MongoDB in any way. The next example will show MongoDB access and other features.
Database “CopyBuilder”¶
The next builder does a simple DB operation: copying one MongoDB collection from a source to a destination. As before, we begin with the full program and then step through it one snippet at at time:
from pymatgen.db.builders import core, util
from pymatgen.db.query_engine import QueryEngine
_log = util.get_builder_log("copy")
class CopyBuilder(core.Builder):
"""Copy from one MongoDB collection to another.
"""
def __init__(self, *args, **kwargs):
self._target_coll = None
core.Builder.__init__(self, *args, **kwargs)
def get_items(self, source=None, target=None, crit=None):
"""Copy records from source to target collection.
:param source: Input collection
:type source: QueryEngine
:param target: Output collection
:type target: QueryEngine
:param crit: Filter criteria, e.g. "{ 'flag': True }".
:type crit: dict
"""
self._target_coll = target.collection
if not crit: # reduce any False-y crit value to None
crit = None
cur = source.query(criteria=crit)
_log.info("copy: source={} crit={} count={:d}"
.format(source.collection, crit, len(cur)))
return cur
def process_item(self, item):
self._target_coll.insert(item)
Logging:
_log = util.get_builder_log("copy")
In this program, we start by setting up logging.
For convenience, the util.get_builder_log() method creates a new
Python logging.Logger instance with a standard name and format.
Initialization:
def __init__(self, *args, **kwargs):
self._target_coll = None
core.Builder.__init__(self, *args, **kwargs)
When we initialize the class, we create an instance variable that we will later use to remember the target collection.
get_items:
def get_items(self, source=None, target=None, crit=None):
"""Copy records from source to target collection.
:param source: Input collection
:type source: QueryEngine
:param target: Output collection
:type target: QueryEngine
:param crit: Filter criteria, e.g. "{ 'flag': True }".
:type crit: dict
"""
self._target_coll = target.collection
if not crit: # reduce any False-y crit value to None
crit = None
cur = source.query(criteria=crit)
_log.info("source={} crit={} count={:d}"
.format(source.collection, crit, len(cur)))
return cur
For a copy operation, the get_items() method must query the source
collection and get an iterator over the records.
There are two things that are different from the FileCounter example.
First, note that there is no get_parameters() method at all. Instead
the docstring of this method is actually a machine-readable version of
the metadata needed for running the builder. Not coincidentally, the format
expected by this docstring is also understood by Sphinx’s autodoc feature.
This way, you will be able to kill two birds with one stone: your builders
will be documented for command-line invocation, and you can easily generate
HTML, PDF, etc. documentation pages.
Second, this method connects to the database and queries it. But, you may
be asking, where is the db.connect() call? This is handled by some magic
that is in the docstring. Notice that the type of both the source and
target is QueryEngine. This is a special datatype that instructs the
driver program (mgbuild) to expect a database configuration file with
host name, user, password, database name, etc. and to automatically connect
to this database and return a pymatgen.db.query_engine.QueryEngine instance.
These instances are passed in as arguments to the method. So, all the
method has to do is to use the QueryEngine object. In this case,
this means creating a cursor that iterates over the source collection
and remembering the target collection in an instance variable.
Note
Unlike the previous example where instance variables might cause
strange behavior, here the _target_coll instance variable is
perfectly fine for parallel execution because the individual
builder instances do not want to share the state of this variable
between them – they each want and need their own copy.
process_item:
def process_item(self, item):
self._target_coll.insert(item)
Here, we simply insert every item into the target collection.
As we will see later, the builder framework also contains some automatic functionality for incremental building, which means only looking at records that are new since the last time. Usually this involves some extra logic inside the builder itself, but in a very simple case like this the copying would automatically work with the incremental mode.
Incremental builder “MaxValueBuilder”¶
The incremental building concept was introduced in Features.
The central idea of the incremental building implementation is that any builder
can be run in “incremental mode”. When this happens, any QueryEngine objects
are replaced transparently by equivalent objects that track their last
position, of class pymatgen.db.builders.incr.TrackedQueryEngine, which is
documented in module pymatgen.db.builders.incr. This tracking can be
controlled, if necessary, with the instance variable tracking on the
TrackedQueryEngine class.
The Database “CopyBuilder” is an example of a trivial builder that can work with incremental building, without modification to the source code. With incremental mode activated, successive copies will only move over “new” data items. But most builders will not be this easy. To help understand what to do in a non-trivial case, we show here a contrived example where a collection A is used to build a derived collection B. In A, there are 2 values for each record, a number and a group name. In B, there are two values for each distinct group in A: the group name, and the highest value for that group.
For the sake of this example we will use the following algorithm to rebuild B from A when A gets new elements Anew.
For each record present in Anew:
Get its group, g
If g is not seen, figure out current maximum (if any) from all records in A
Update maximum for g, in memory, with value for record
After all records in Anew are processed, set new group maximums in B from values stored in memory.
This algorithm is incremental in the sense that it ignores any groups that are not in the new elements Anew, yet non-trivial because in order to calculate the new maximum value one needs to examine all the elements in A:
from pymatgen.db.builders import core
from pymatgen.db.builders import util
from pymatgen.db.query_engine import QueryEngine
class MaxValueBuilder(core.Builder):
"""Example of incremental builder that requires
some custom logic for incremental case.
"""
def get_items(self, source=None, target=None):
"""Get all records from source collection to add to target.
:param source: Input collection
:type source: QueryEngine
:param target: Output collection
:type target: QueryEngine
"""
self._groups = self.shared_dict()
self._target_coll = target.collection
self._src = source
return source.query()
def process_item(self, item):
"""Calculate new maximum value for each group,
for "new" items only.
"""
group, value = item['group'], item['value']
if group in self._groups:
cur_val = self._groups[group]
self._groups[group] = max(cur_val, value)
else:
# New group. Could fetch old max. from target collection,
# but for the sake of illustration recalculate it from
# the source collection.
self._src.tracking = False # examine entire collection
new_max = value
for rec in self._src.query(criteria={'group': group},
properties=['value']):
new_max = max(new_max, rec['value'])
self._src.tracking = True # back to incremental mode
# calculate new max
self._groups[group] = new_max
def finalize(self, errs):
"""Update target collection with calculated maximum values.
"""
for group, value in self._groups.items():
doc = {'group': group, 'value': value}
self._target_coll.update({'group': group}, doc, upsert=True)
return True
Initialization:
class MaxValueBuilder(core.Builder):
"""Example of incremental builder that requires
some custom logic for incremental case.
"""
def get_items(self, source=None, target=None):
"""Get all records from source collection to add to target.
:param source: Input collection
:type source: QueryEngine
:param target: Output collection
:type target: QueryEngine
"""
self._groups = self.shared_dict()
self._target_coll = target.collection
self._src = source
return source.query()
Just as for the CopyBuilder, we use the docstring-style of declaration for the
parameters to this builder, which are simply the input and output collections.
We remember both source and target in variables. In addition, we use a utility
function shared_dict() in the Builder class to get a dictionary variable
that can be shared between parallel processes. Finally, this method returns
a query on all items in the collection.
Processing:
def process_item(self, item):
"""Calculate new maximum value for each group,
for "new" items only.
"""
group, value = item['group'], item['value']
if group in self._groups:
cur_val = self._groups[group]
self._groups[group] = max(cur_val, value)
else:
# New group. Could fetch old max. from target collection,
# but for the sake of illustration recalculate it from
# the source collection.
self._src.tracking = False # examine entire collection
new_max = value
for rec in self._src.query(criteria={'group': group},
properties=['value']):
new_max = max(new_max, rec['value'])
self._src.tracking = True # back to incremental mode
# calculate new max
self._groups[group] = new_max
For each item, we update the shared _groups variable created in
get_items(). For new groups, we re-scan the whole source collection
to find the previous maximum value.
There are a couple better ways to do this,
but this method is easy to understand and illustrates how a collection
can be manipulated in its “raw” form in an incremental builder.
The key lines here are
self._src.tracking = False and, later, self._src.tracking = True.
These turn off the “incremental mode” so that the query will start at the
beginning of the collection instead of from the start of Anew.
Finalization:
def finalize(self, errs):
"""Update target collection with calculated maximum values.
"""
for group, value in self._groups.items():
doc = {'group': group, 'value': value}
self._target_coll.update({'group': group}, doc, upsert=True)
return True
In this case, the finalize() method is used to set the calculated
group maximums into the target collection. This is the same as the reduce
stage of a map/reduce task (the process_item performs the map).
In conclusion, we see that for this case only 2 lines turning the tracking variable on and off needed to be added to accommodate incremental building.
Running a builder¶
This section describes how, once you have written a builder class, you can use mgbuild to run it, possibly in parallel and possibly “incrementally”, on some inputs.
We will break this process into two parts:
Displaying the usage for a given builder class
Running the builder
Both of these use the mgbuild sub-command “run” (alternatively: “build”), like this:
mgbuild run <arguments>
In the examples below, we will assume that you have pymatgen-db installed and
in your Python path. We will use the example modules that are installed
in pymatgen.db.builders.examples.
Displaying builder usage¶
You can get the list of parameters and their types for a given builder
by giving its full module path, and the -u or --usage option:
% mgbuild run -u pymatgen.db.builders.examples.copy_builder.CopyBuilder
pymatgen.db.builders.examples.copy_builder.CopyBuilder
Copy from one MongoDB collection to another.
Parameters:
crit (dict): Filter criteria, e.g. "{ 'flag': True }".
source (QueryEngine): Input collection
target (QueryEngine): Output collection
Note
You will also get the usage information if you invoke the builder with the wrong number of arguments (e.g. zero), although in this case you will also see some error messages.
Running the builder¶
The usage of the mgbuild run command is as follows:
usage: mgbuild run [-h] [--quiet] [--verbose] [-i OPER[:FIELD]] [-n NUM_CORES]
[-u]
builder [parameter [parameter ...]]
positional arguments:
builder Builder class, relative or absolute import path, e.g.
'my.awesome.BigBuilder' or 'BigBuilder'.
parameter Builder parameters, in format <name>=<value>. If the
parameter type is QueryEngine, the value should be a
JSON configuration file. Prefix filename with a '-' to
ignore incremental mode for this QueryEngine.
optional arguments:
-h, --help show this help message and exit
--quiet, -q Minimal verbosity.
--verbose, -v Print more verbose messages to standard error.
Repeatable. (default=ERROR)
-i OPER[:FIELD], --incr OPER[:FIELD]
Incremental mode for operation and optional sort-field
name. OPER may be one of: copy, other, build. Default
FIELD is '_id'
-n NUM_CORES, --ncores NUM_CORES
Number of cores or processes to run in parallel (1)
-u, --usage Print usage information on selected builder and exit.
To run the builder, you need at a minimum to give the full path to the builder class, and then values for each parameter. There are also optional arguments for building in parallel and building incrementally. This section will walk through from simple to more complex examples.
Basic usage¶
Run the copy builder:
mgbuild run pymatgen.db.builders.examples.copy_builder.CopyBuilder \
source=conf/test1.json target=conf/test2.json crit='{}'
In this example, we are running the CopyBuilder with configuration files for the source and target and empty criteria (i.e. copy everything). The copy will be run in a single thread.
The configuration files in question are just JSON files that look like this (you could add “user” and “password” for authenticated DBs):
{"host": "localhost", "port": 27017,
"database": "foo", "collection": "test1"}
See Database configuration for more details.
Running in parallel¶
Most machines have multiple cores, and hundreds of cores will be common in the near future. If your item processing requires any real work, you will probably benefit by running in parallel:
mgbuild run pymatgen.db.builders.examples.copy_builder.CopyBuilder \
source=conf/test1.json target=conf/test2.json crit='{}' -n 8
The same command as previously, but with -n 8 added to cause 8 parallel threads to be spawned to run the copy in parallel.
Note
For parallel runs, only the process_item() method is run in parallel.
The get_items() is always run sequentially.
Incremental builds¶
The concept of incremental building was introduced in Incremental builder “MaxValueBuilder”.
From the command-line, incremental building is controlled by the -i/--incr option.
What this really does is to add some behind-the-scenes bookkeeping for every
parameter of type QueryEngine (except ones where it is explicitly
turned off, see below) that records and retrieves the spot where processing
was last ended. Multiple spots are allowed per-collection by requiring an
“operation”. Currently,
only a small set of operations are allowed: “copy”, “build”, and “other”.
For incremental building to work properly, there must be some field in the collection that increases monotonically. This field is used to determine which records come after the spot marked on the last run. By default this field is _id, but it is highly recommended to choose a collection-specific identifier because _id as chosen by the client is not always monotonic.
Basic incremental build:
mgbuild run pymatgen.db.builders.examples.copy_builder.CopyBuilder \
source=conf/test1.json target=conf/test2.json crit='{}' \
-i copy
Copies from source to target. Subsequent runs will only copy records that
are newer (according to the field, in this case defaulting to _id)
than the last record from the previous run.
Incremental build with parallelism:
mgbuild run pymatgen.db.builders.examples.copy_builder.CopyBuilder \
source=conf/test1.json target=conf/test2.json crit='{}' \
-n 8 -i copy
Parallelism is not different with incremental builds. As before, we simply add -n 8 to the command-line.
Incremental build with custom identifier:
mgbuild run pymatgen.db.builders.examples.copy_builder.CopyBuilder \
source=conf/test1.json target=conf/test2.json crit='{}' \
-i copy:num
This example runs an incremental build with the “copy” operation,
using the num field instead of the default _id.
Incremental build skipped for some collections:
mgbuild run pymatgen.db.builders.examples.copy_builder.CopyBuilder \
source=conf/test1.json target=-conf/test2.json crit='{}' \
-i copy:num
This is pretty subtle: notice the “-” inserted after the “=” in
target=-conf/test2.json. This has the effect of not adding tracking information
for the target collection.
In this case, tracking the last record added to the target
isn’t useful for the copy, all that matters is knowing where we stopped
in the source collection.